Inference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps

Generative models have made significant impacts across various domains, largely due to their ability to scale during training by increasing data, computational resources, and model size, a phenomenon characterized by the scaling laws. Recent research has begun to explore inference-time scaling behavior in Large Language Models (LLMs), revealing how performance can further improve with additional computation during inference. Unlike LLMs, diffusion models inherently possess the flexibility to adjust inference-time computation via the number of denoising steps, although the performance gains typically flatten after a few dozen. In this work, we explore the inference-time scaling behavior of diffusion models beyond increasing denoising steps and investigate how the generation performance can further improve with increased computation.
Specifically, we consider a search problem aimed at identifying better noises for the diffusion sampling process. We structure the design space along two axes: the verifiers used to provide feedback, and the algorithms used to find better noise candidates. Through extensive experiments on class-conditioned and text-conditioned image generation benchmarks, our findings reveal that increasing inference-time compute leads to substantial improvements in the quality of samples generated by diffusion models, and with the complicated nature of images, combinations of the components in the framework can be specifically chosen to conform with different application scenario.
In recent years a family of flexible generative model
based on transforming pure noise \(\varepsilon \sim \mathcal{N}(0, \mathbf{I})\) into data \(x_* \sim p(x)\) has emerged.
This transformation can be described by a simple time-dependent process $$
x_t = \alpha_t x_* + \sigma_t \varepsilon
$$
with t defined on \([0, T]\), \(\alpha_t, \sigma_t\) being time-dependent functions and chosen such that \(x_0 \sim p(x)\), \(x_T \sim \mathcal{N}(0, \mathbf{I})\).
At each \(t\), \(x_t\) has a conditional density \(p_t(x | x_*) = \mathcal{N}(\alpha_t x_*, \sigma_t^2\mathbf{I})\),
and our goal is to estimate the marginal density \(p_t(x) = \int p_t(x | x_*) p(x) \mathrm{d}x \).
Diffusion-Based
These generation processes usually starts from pure noise and requires multiple forward passes of trained models to denoise and obtain clean data.
These forward passes are thus dubbed denoising steps. Since the number of denoising steps can be adjusted to trade sample quality for computational cost, the generation process of diffusion models naturally provides flexibility in allocating inference-time computation budget.
Under the context of generative models, such computation budget is also commonly measured by the number of function evaluations (NFE), to ensure a reasonable comparison with other families of models that use iterative sampling processes but without denoising capabilities
In theory, there is explicit randomness in the sampling of diffusion models: the randomly drawn initial noise, and the optional subsequent noise injected via procedures like SDE
We frame the inference-time scaling as a search problem over the sampling noises; in particular, how do we know which sampling noises are good, and how do we search them?
On a high-level, there are two design axes we propose to consider:
Oracle Verifier, which utilizes full privileged information about the final evaluation of the selected samples.
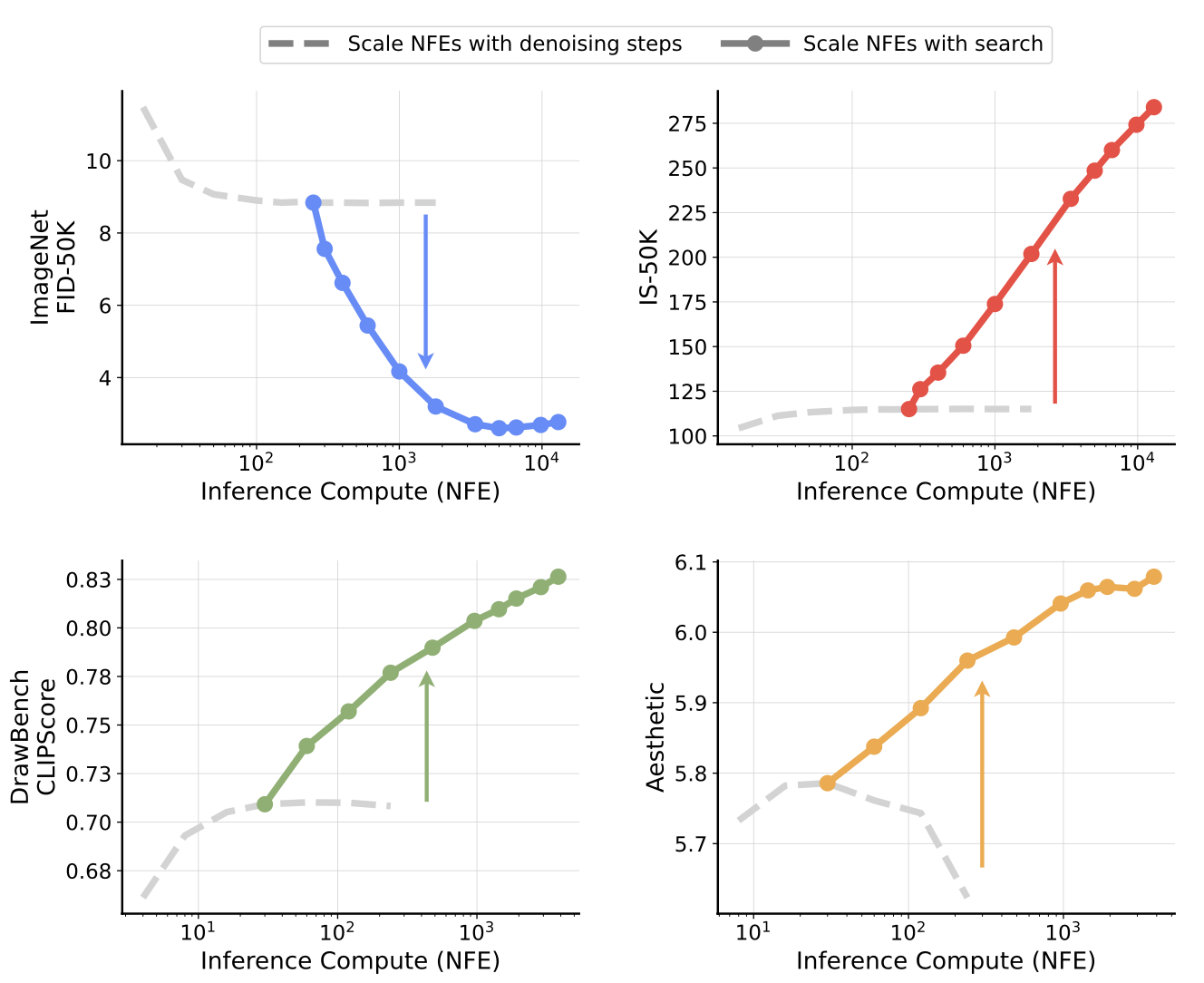
On ImageNet, we directly take the most commonly-used FID and IS as the oracle verifiers.
For IS, we select the samples with highest classification probability output by a pretrained InceptionV3 model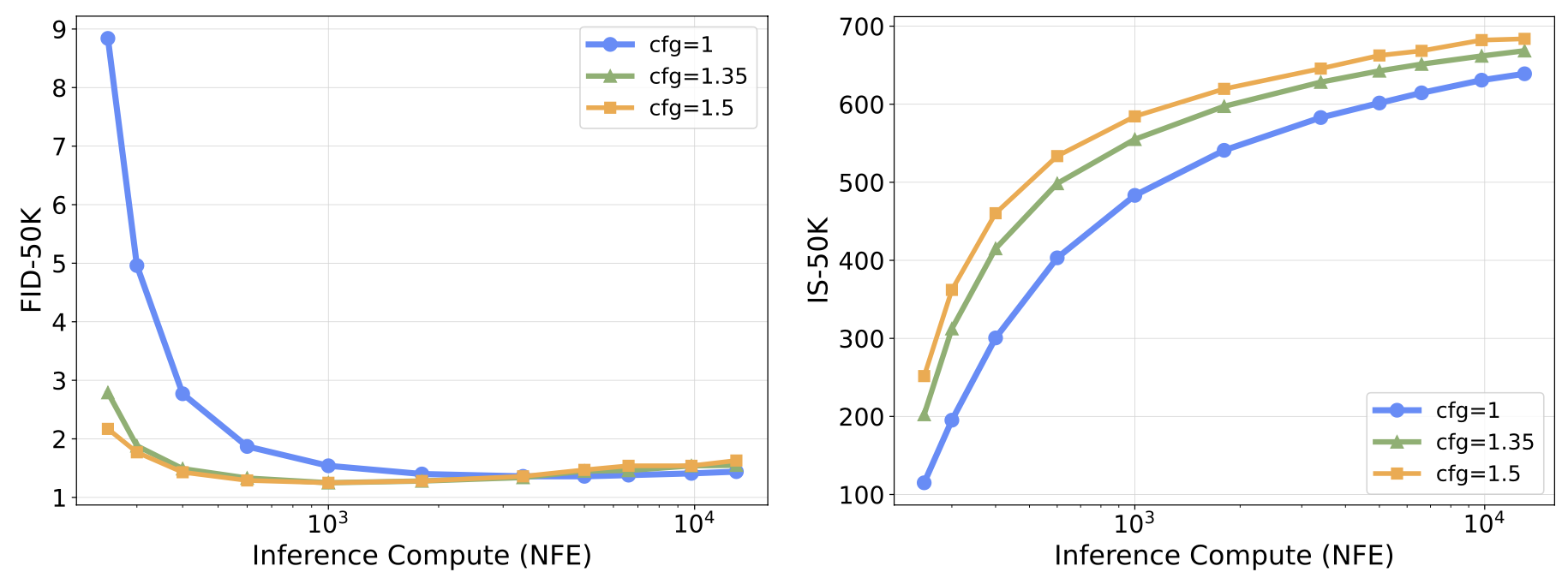
Supervised Verifier, which has access to pre-trained models for evaluating both the quality of the samples
and their alignment with the specified conditioning inputs. This is a more realistic setup as the pre-trained models are not directly linked to the final evaluation of the samples, and
we want to investigate if the supervised verifiers can still provide reasonable feedbacks and enable effective inference-time scaling.
Although this strategy effectively improves the IS of the samples comparing to purely scaling NFEs with increased denoising steps, the classifiers we use are only partially aligned with the goal of FID score,
since they operate point-wise and do not consider the global statistics of the samples. This can lead to a significant reduction in sample variance and eventually manifests as mode collapse as the compute increases,
as demonstrated below by the increasing Precision and the decreasing Recall.

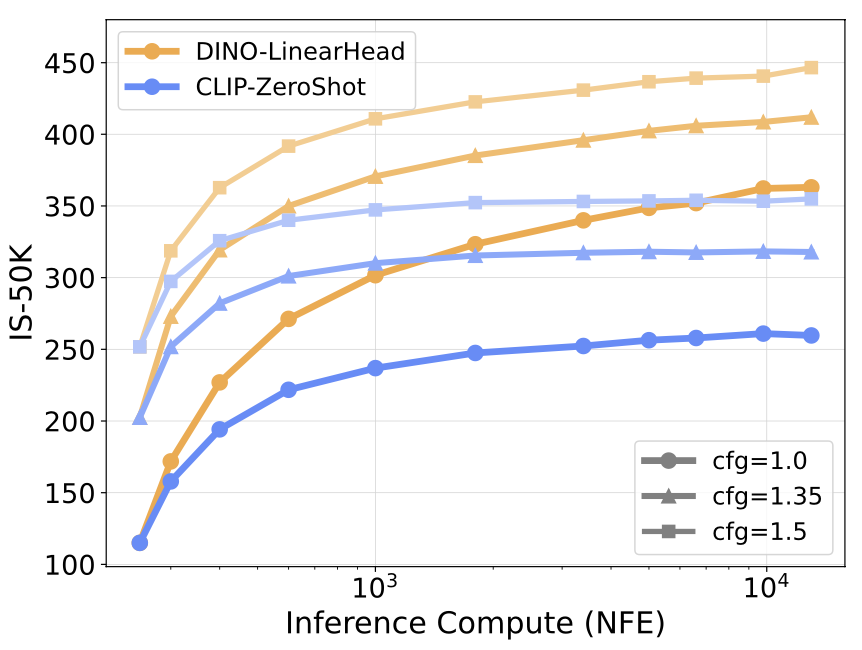
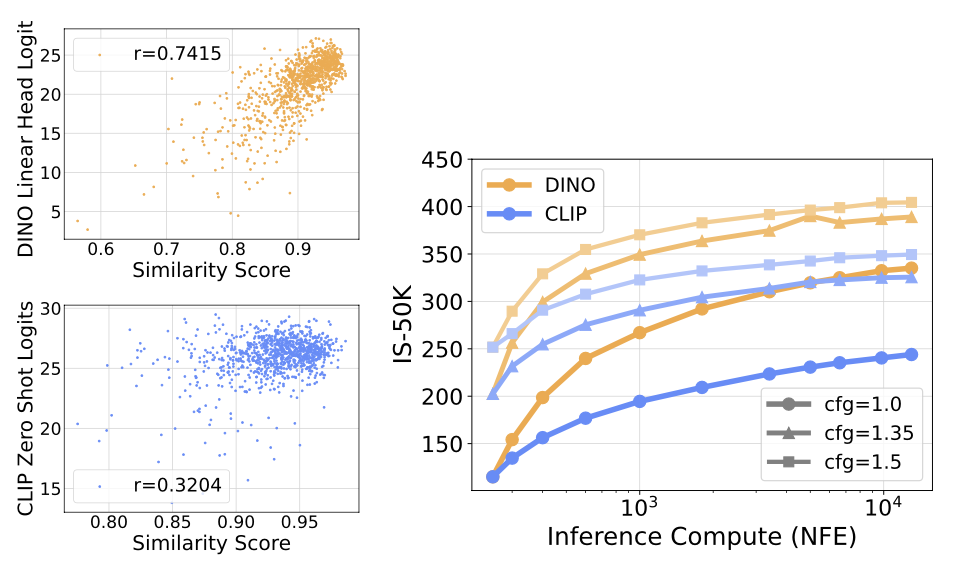
Self-Supervised Verifier, which uses the feature space (extracted by DINO / CLIP, respectively) cosine similarity of samples at low noise level (\( \sigma = 0.4 \)) and clean samples (\(\sigma = 0.0\)) to evaluate the quality of initial noises.
We found that such similarity score is highly correlated with the logits output by the DINO / CLIP classifiers, and thus use it as an effective surrogate for the supervised verifier, as demonstrated below.
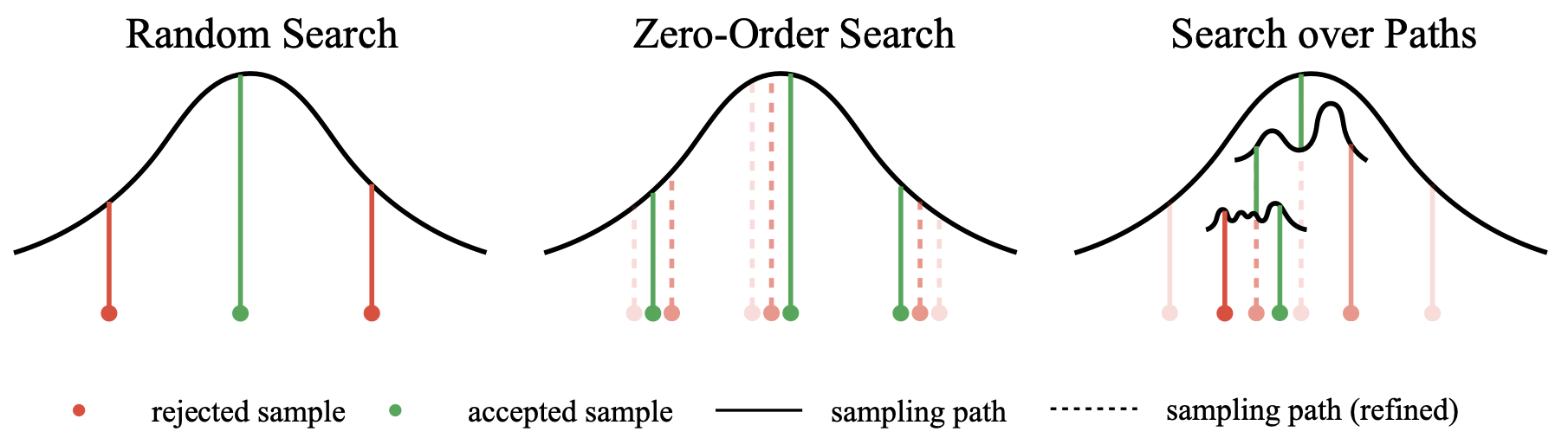
Random Search, which is essentially a Best-of-N strategy applied once on all noise candidates, and the primary axis for scaling NFEs in search is simply the number of noise candidates to select from.
Its effectiveness has been demonstrated in previous section, and we note that since its search space is unconstrained, it accelerates the converging of search towards the bias of verifiers,
leading to the loss in diversity. Such phenomenon is similar to reward hacking in reinforcement learning
Zero-Order Search, which is similar to Zero-Order Optimization
Search over Paths, which iteratively refine the diffusion trajectory, and we specified the detailed procedure below.

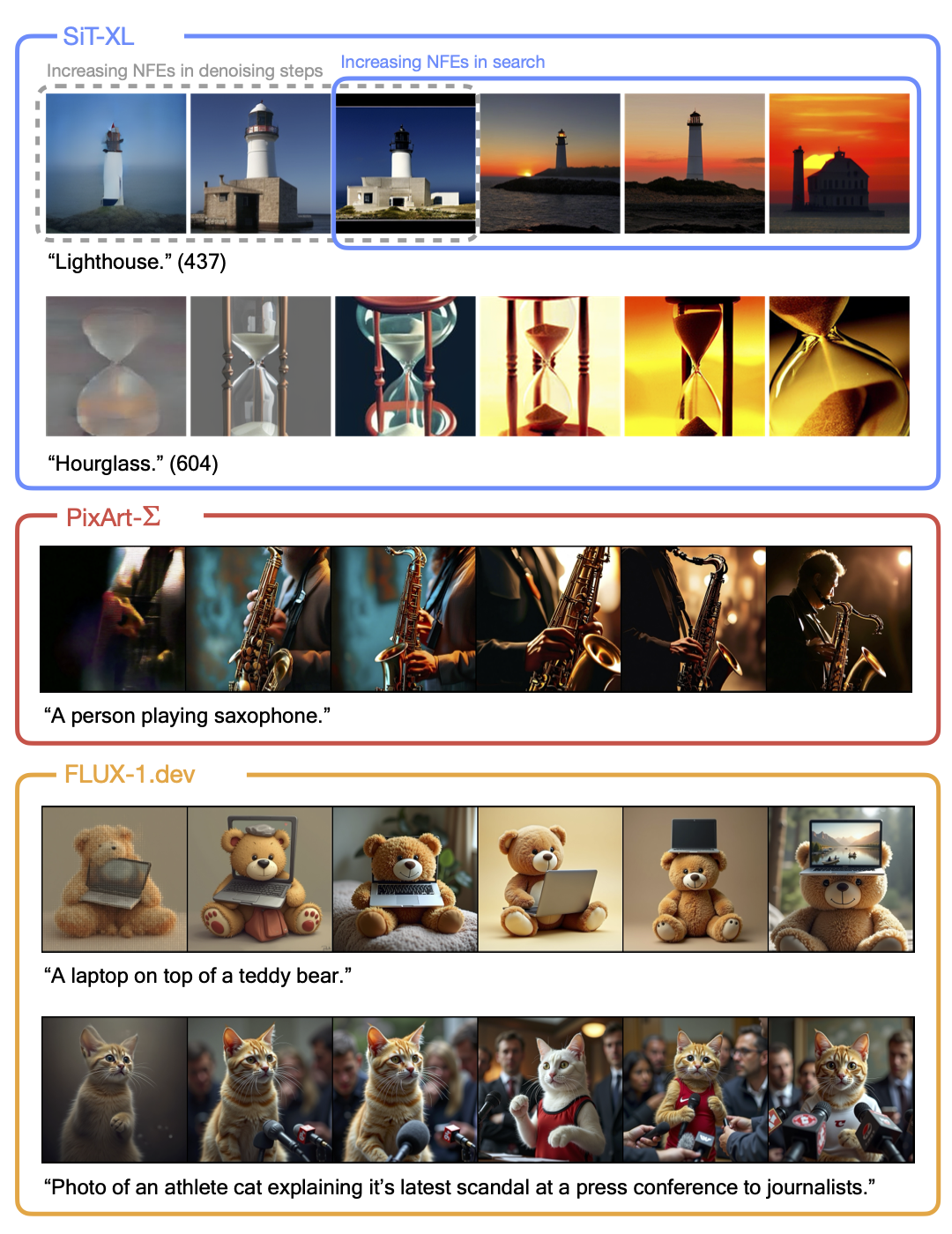
With the instantiation of our search framework, we proceed to examine its inference-time scaling capability in larger-scale text-conditioned generation tasks, and study the alignment between verifiers and specific image generation tasks.
Datasets. For a more holistic evaluation of our framework, we use two datasets: DrawBench
Models. We use the newly released FLUX.1-dev model
Verifiers. We expand the choice of verifiers to cope with the complex nature of text-conditioned image generation: Aesthetic Score Predictor
Metrics. On DrawBench, we use all verifiers not employed in the search process as primary metrics to provide a more comprehensive evaluation. Considering the usage of Verifier Ensemble, we additionally introduce an LLM grader as a neutral evaluator for assessing sample qualities.
We prompt the Gemini-1.5 model to assess synthesized images from five different perspectives: Accuracy to Prompt, Originality, Visual Quality, Internal Consistency, and Emotional Resonance.
Each perspective is rated on a scale from 0 to 100, and the averaged overall score is used as the final metric.
On T2I-CompBench, we use the evaluation pipeline provided to assess the performance of our framework in compositional generation tasks.
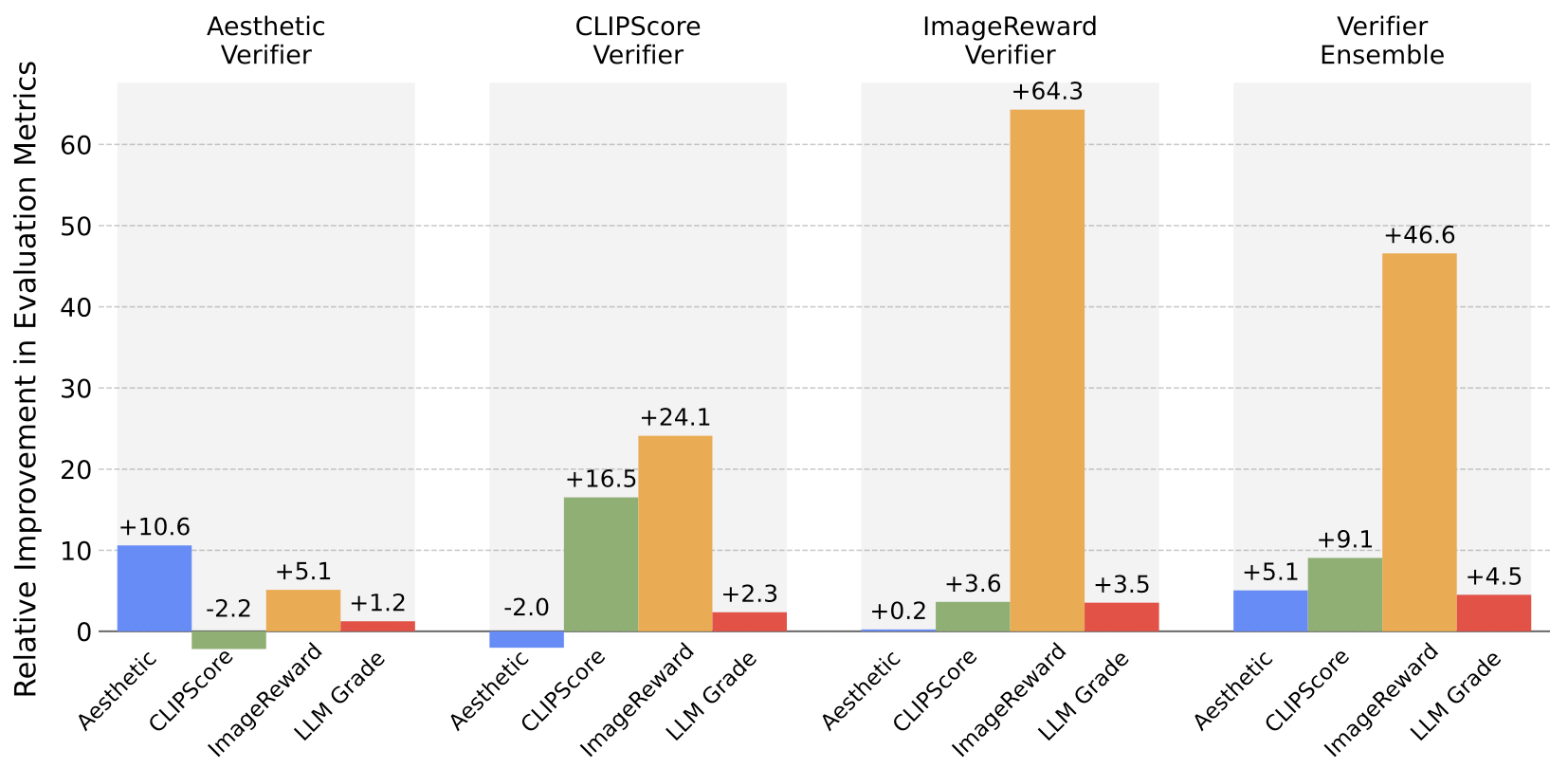
DrawBench. As shown above, and as indicated by the LLM Grader, searching with all verifiers generally improves sample quality, while specific improvement behaviors vary across different setups:
Yet, since searching with Aesthetic and CLIP does not lead to a total collapse in sample quality, they can be well-suited for tasks that require a focus on specific attributes such as visual appeal or textual accuracy, rather than maintaining general-purpose performance. These different behaviors across verifiers highlight the importance of aligning verifiers with the specific task at hand.
T2I-CompBench. Since T2I-CompBench emphasize correctness in relation to the text prompt, we see that ImageReward becomes the best verifier, whereas Aesthetic Score leads to minimal improvements and even degradation, as demonstrated below.
| Verifier | Color | Shape | Texture | Spatial | Numeracy | Complex |
|---|---|---|---|---|---|---|
| - | 0.7692 | 0.5187 | 0.6287 | 0.2429 | 0.6167 | 0.3600 |
| Aesthetic | 0.7618 | 0.5119 | 0.5826 | 0.2593 | 0.6159 | 0.3472 |
| CLIP | 0.8009 | 0.5722 | 0.7005 | 0.2988 | 0.6457 | 0.3704 |
| ImageReward | 0.8303 | 0.6274 | 0.7364 | 0.3151 | 0.6789 | 0.3810 |
| Ensemble | 0.8204 | 0.5959 | 0.7197 | 0.3043 | 0.6623 | 0.3754 |
These contrasting behaviors of verifiers on DrawBench and T2I-CompBench highlight how certain verifiers can be better suited for particular tasks than others. This inspires the design of more task-specific verifiers, which we leave as future works.
Algorithms. Below we demonstrate the performance of search algorithms on DrawBench. For Zero-Order Search, we set the number of neighbors to be \(N = 2\). For Search over Paths, we set the number of initial noises to be \(N = 2\) as well.
| Verifier | Aesthetic | CLIPScore | ImageReward | LLM Grader |
|---|---|---|---|---|
| - | 5.79 | 0.71 | 0.97 | 84.29 |
| Aesthetic + Random | 6.38 | 0.69 | 0.99 | 86.04 |
| + ZO-2 | 6.33 | 0.69 | 0.96 | 85.90 |
| + Paths-2 | 6.31 | 0.70 | 0.95 | 85.86 |
| CLIPScore + Random | 5.68 | 0.82 | 1.22 | 86.15 |
| + ZO-2 | 5.72 | 0.81 | 1.16 | 85.48 |
| + Paths-2 | 5.71 | 0.81 | 1.14 | 85.45 |
| ImageReward + Random | 5.81 | 0.74 | 1.58 | 87.09 |
| + ZO-2 | 5.79 | 0.73 | 1.50 | 86.22 |
| + Paths-2 | 5.76 | 0.74 | 1.49 | 86.33 |
| Ensemble + Random | 6.06 | 0.77 | 1.41 | 88.18 |
| + ZO-2 | 5.99 | 0.77 | 1.38 | 87.25 |
| + Paths-2 | 6.02 | 0.76 | 1.34 | 86.84 |
We see that all three methods can effectively improve the sampling quality, with random search outperforming the other two methods in some aspects, due to the locality nature of Zero-Order Search and Search over Paths.
Both search and finetuning methods
We take the DPO fine-tuned Stable Diffusion XL model
| Model | Aesthetic | CLIP | PickScore |
|---|---|---|---|
| SDXL | 5.56 | 0.73 | 22.39 |
| + DPO | 5.59 | 0.74 | 22.54 |
| + DPO & Search | 5.66 | 0.76 | 23.54 |
We see that search method can generalize to different models and can improve the performance of an already aligned model. This will be a useful tool to mitigate the cases where finetuned models disagree with reward models and to improve their generalizability.
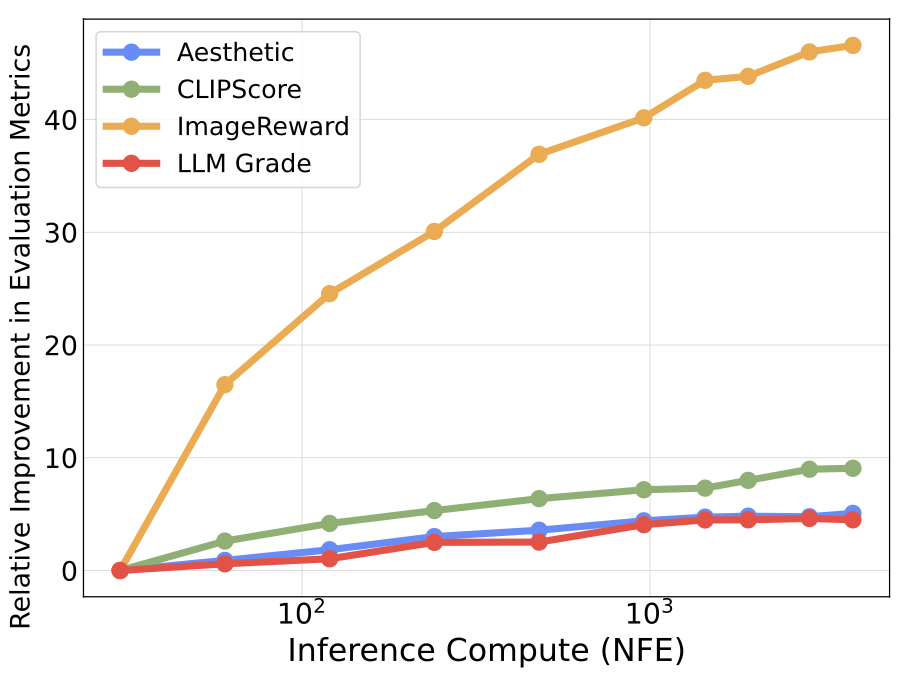
Number of search iterations. Increasing the allows the selected noises to approach the optimal set with respect to verifiers. We observed such behavior in all of our previous experiments.
Compute per search iteration. We denote such compute NFEs/iter. During search, adjusting NFEs/iter can reveal distinct compute-optimal regions, as shown below.
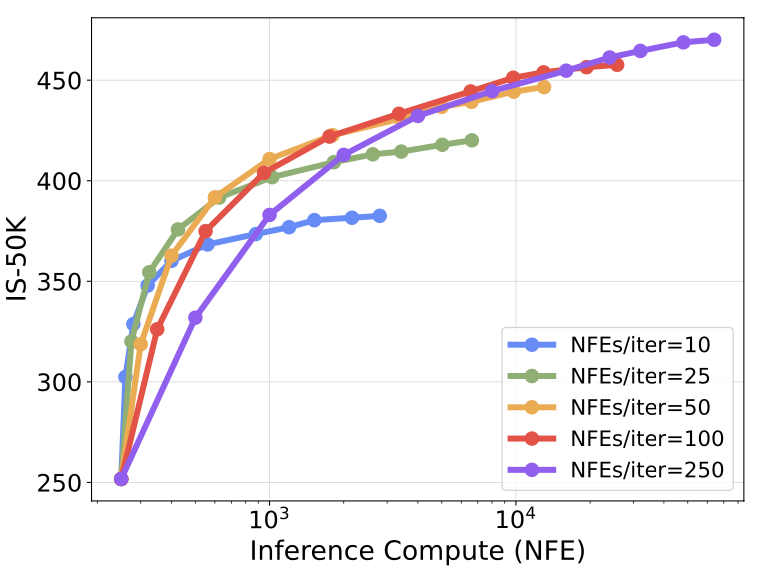
We explore the effectiveness of scaling inference-time compute for smaller diffusion models and highlight its efficiency relative to the performance
of their larger counterparts without search.
For ImageNet tasks, we utilize SiT-B and SiT-L, and for text-to-image tasks, we use the smaller transformer-based model PixArt-\(\Sigma\)
Since models of different sizes incur significantly different costs per forward pass, we use estimated GFLOPs to measure their computational cost instead of NFEs.
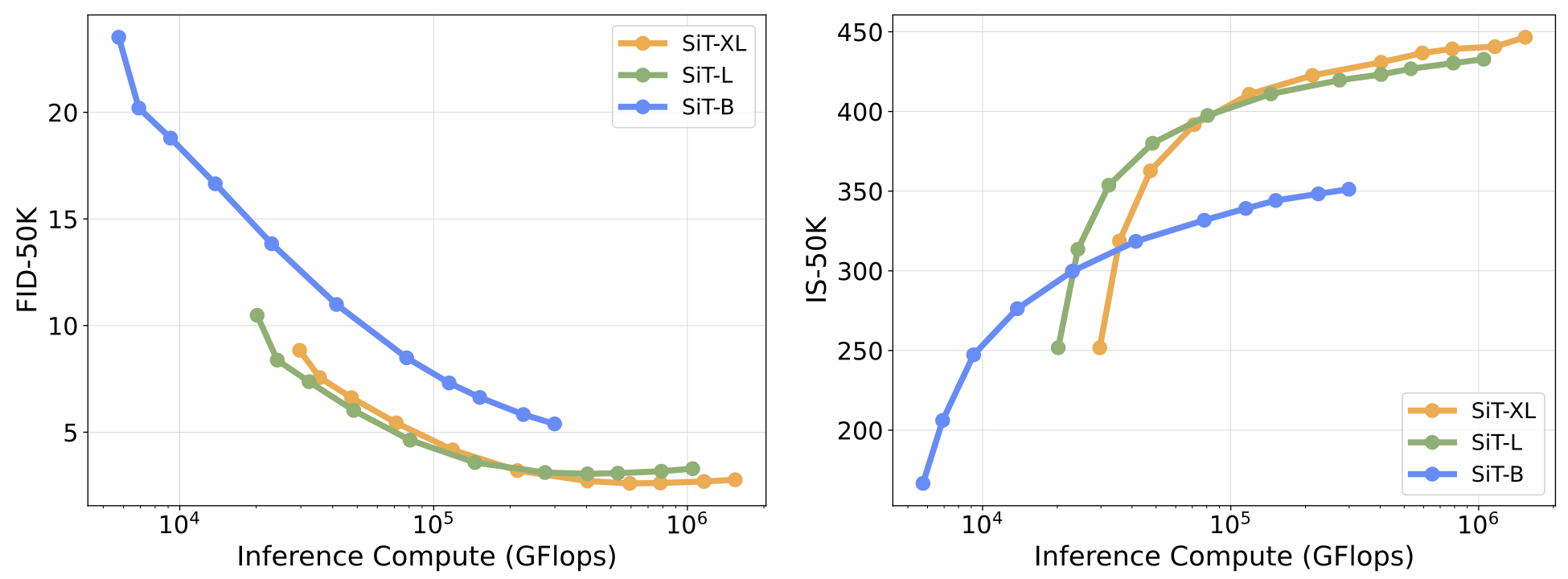
As shown above, scaling inference-time compute for small models on ImageNet can be highly effective - fixing compute budget, SiT-L can outperform SiT-XL in regions with limited inference compute. Yet, this requires the small model to have a relatively strong performance - SiT-B does not benefit from search as much as SiT-L and does not have an advantageous compute region.
These observations extend to the text-conditioned setting, as demonstrated below. With just one-tenth of the compute, PixArt-\(\Sigma\) outperforms FLUX- 1.dev without search, and with roughly double the compute, PixArt-\(\Sigma\) surpasses FLUX.1-dev without search by a significant margin. These results have important practical implications: the substantial compute resources invested in training can be offset by a fraction of that compute during generation, enabling access to higher-quality samples more efficiently.
| Model | Compute Ratio | Aesthetic | CLIP | ImageReward | LLM Grader |
|---|---|---|---|---|---|
| FLUX | 1 | 5.79 | 0.71 | 0.97 | 84.29 |
| PixArt-\(\Sigma\) | ~0.06 | 5.94 | 0.68 | 0.70 | 84.67 |
| ~0.09 | 6.03 | 0.71 | 0.97 | 85.62 | |
| ~2.59 | 6.20 | 0.73 | 1.15 | 86.95 | |
In this work, we present a framework for inference-time scaling in diffusion models, demonstrating that scaling compute through search could significantly improve performances across various model sizes and generation tasks, and different inference-time compute budget can lead to varied scaling behavior. Identifying verifiers and algorithms as two crucial design axes in our search framework, we show that optimal configurations vary by task, with no universal solution. Additionally, our investigation into the alignment between different verifiers and generation tasks uncovers their inherent biases, highlighting the need for more carefully designed verifiers to align with specific vision generation tasks.
@article{ma2025inferencetimescalingdiffusionmodels,
title={Inference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps},
author={Nanye Ma and Shangyuan Tong and Haolin Jia and Hexiang Hu and Yu-Chuan Su and Mingda Zhang and Xuan Yang and Yandong Li and Tommi Jaakkola and Xuhui Jia and Saining Xie},
year={2025},
eprint={2501.09732},
archivePrefix={arXiv},
primaryClass={cs.CV}
}